前几天不是把家里的小霸王给改造成了NAS嘛,然后本来就是想架个EMBY然后在家里直接就看番了的,找了一圈发现BT下载是比较好用的,结果下载下来文件名格式又不一样,不符合EMBY的解析要求,于是就有了这篇文章
找种子
我推荐用蜜柑计划 - Mikan Project (mikanani.me)
虽然有时候上不去,但是资源是全的,速度也很不错,可以试试
配置下载
我一开始用的qbitorrent(群晖套件版的),但是那个配置起来超级麻烦,而且发现RSS订阅后不会自动下载(不知道是我的问题还是啥)
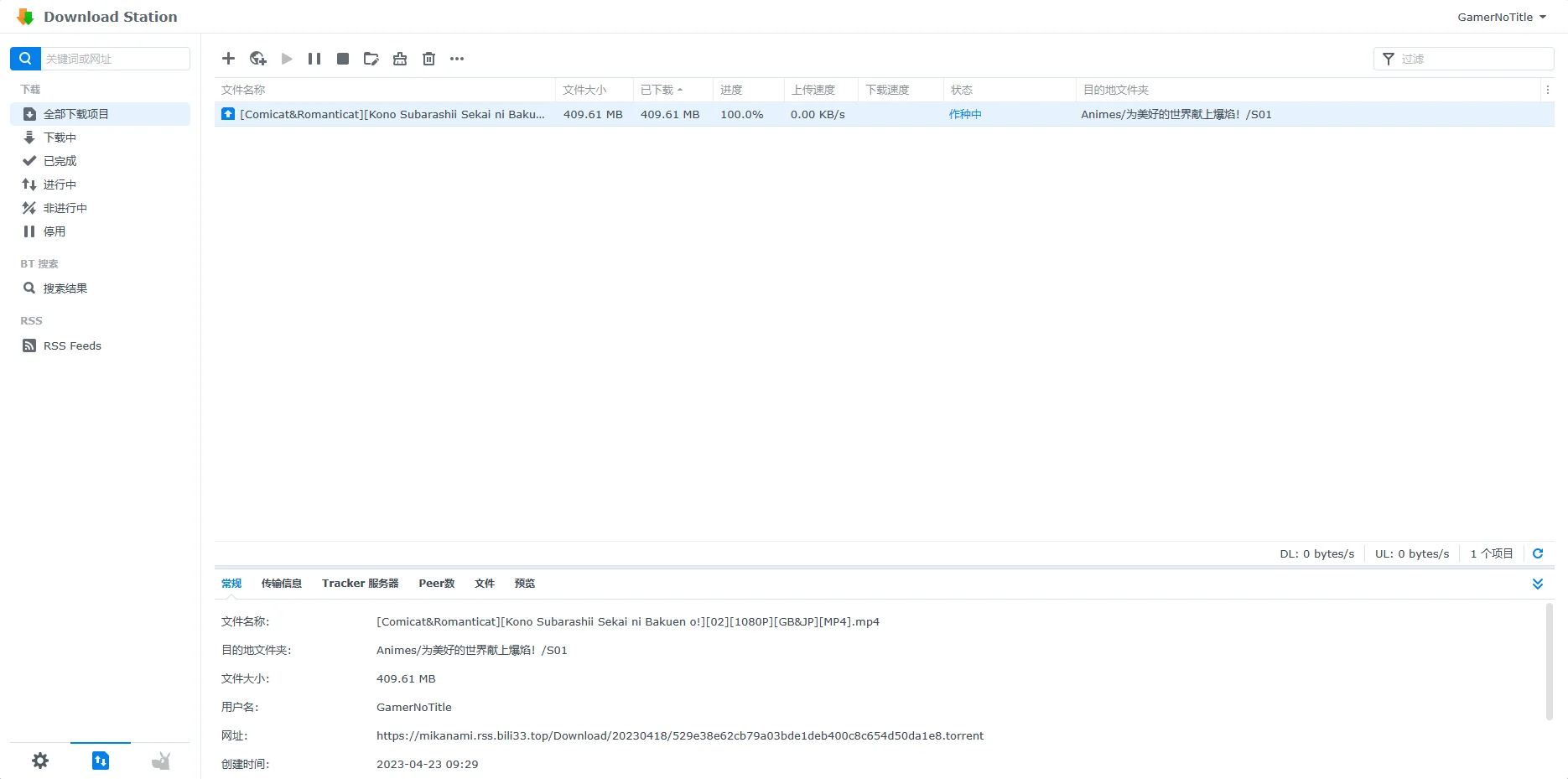
然后我记得群晖里有一个自带的Download Station,启动后发现其实它是支持BT下载的
我们找到Download Station,然后打开RSS,在里面添加我们的RSS链接
我这里选的是那种分集用[]给括起来的字幕组(好正则匹配,后面会说为什么要re匹配),直接加进去就行了
然后在下面下载过滤器新建一个过滤器,根据自己的需要填写过滤规则
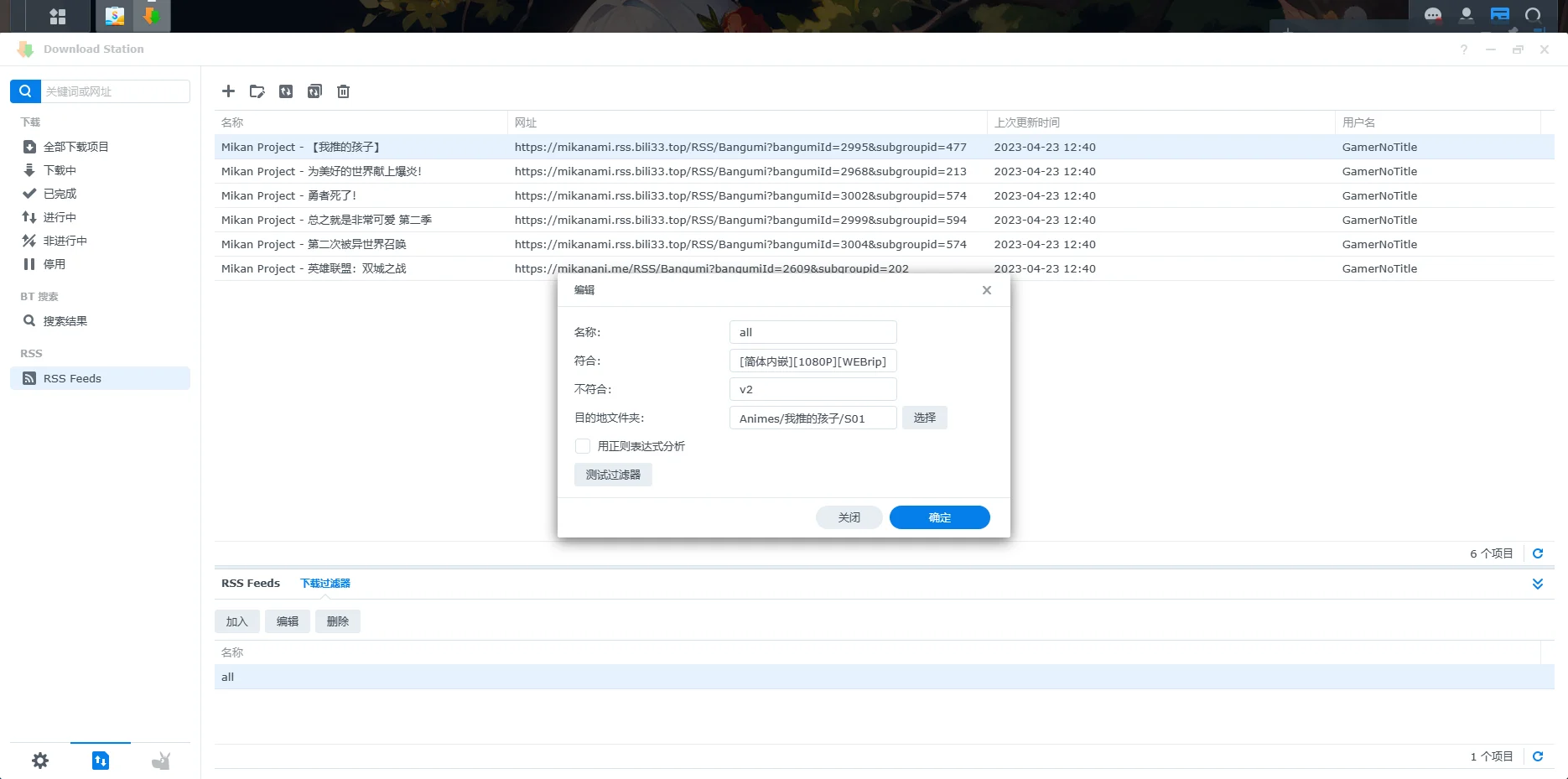
设置完后,记得在RSS Feeds里面,把之前已经发出来的剧集先根据自己的需要下载好
自动重命名
因为EMBY需要AnimeName SxxExx这样的命名格式,但是字幕组发布的资源命名通常都是乱的,所以我们需要配置一个自动重命名
我先写好了一个Python程序,放在/volume1/Storage/AutoRename/AutoRename.py里面(路径可以自己进SSH去找),内容如下
import os
import sys
import re
import time
import shutil
##### 初始化参数 #####
# 工作目录
workdir = '/volume1/Animes'
# 排除目录
ignoredir = [
'@eaDir',
'#recycle'
]
# 日志目录
logdir = '/volume1/Storage/log/synoscheduler/3'
# 日志保留时长(时间戳差,自己去算)【604800 7天】
logpreserve = 604800
# 更改工作目录
os.chdir(workdir)
# 排除目录函数
def RemoveIgnoreDirs(src: list, ignores: list) -> None:
for ignore in ignores:
try:
src.remove(ignore)
except Exception:
pass
# 移除保留时长外的log文件夹的函数
def RemovePreviousLog(src: list, logpreserve: int) -> None:
toRemove = False
loglist = os.listdir(src)
now = int(time.time())
for log in loglist:
try: logtime = int(log)
except Exception as e:
print(f'{e} when removing {logdir}/{log}')
continue
if now - logtime > logpreserve:
toRemove = True
shutil.rmtree(f'{logdir}/{log}')
print(f'Removed {logdir}/{log}')
if not toRemove:
print('Nothing to remove.')
if __name__ == '__main__':
print(f'{" Renameing Animes ":=^60}')
# 获取目录下所有番剧的名字
animes = os.listdir()
RemoveIgnoreDirs(animes, ignoredir)
for anime in animes:
# 获取番剧的季信息
seasons = os.listdir(f'./{anime}')
RemoveIgnoreDirs(seasons, ignoredir)
for season in seasons:
# 获取番剧每一话
episodes = os.listdir(f'./{anime}/{season}')
RemoveIgnoreDirs(episodes, ignoredir)
for episode in episodes:
try:
episode_num = str(re.search(r'\[[0-9][0-9](\.)?[0-9]?(v)?[0-9]?集?\]', episode).group()).replace('[', '').replace(']', '').replace('v2', '').replace('集', '')
except AttributeError:
print(f'No matching pattern on "{episode}"')
continue
filetype = episode.split('.')[-1]
filename = f'{anime} {season}E{episode_num}.{filetype}'
print(f'Renaming "{episode}" -> {filename}')
os.rename(f'./{anime}/{season}/' + episode, f'./{anime}/{season}/' + filename)
# 移除保留期限外的日志
print(f'\n{" Removing old logs ":=^60}')
RemovePreviousLog(logdir, logpreserve)
# 结束提示
print(f'\n{" Done ":=^60}\n')这就是为什么选择字幕组的时候我选了分集号用中括号[]括起来的原因
接着我们打开群晖的控制面板,找到任务计划,新建一个任务
点击新增 -> 用户定义的脚本 根据自己的需要创建即可,一开始在任务名称里面会写Task x,这个x就是你的任务号,群晖的任务log会保存在<你指定的目录>/synoscheduler/<ID>这样的位置,所以这个ID记得记下来然后把脚本里面的ID改掉
保存后群晖就会自动执行重命名任务了,当EMBY进行扫描的时候,扫描到命名正确的文件就会自动加入媒体库了
注:EMBY媒体库的结构举例(也是我这个脚本适合的目录结构)
W:.
├─为美好的世界献上爆焰!
│ └─S01
│ 为美好的世界献上爆焰! S01E01.mp4
│ 为美好的世界献上爆焰! S01E02.mp4
│
├─勇者死了
│ └─S01
│ 勇者死了 S01E01.mp4
│ 勇者死了 S01E02.mp4
│
├─总之就是非常可爱
│ └─S02
│ 总之就是非常可爱 S02E01.mp4
│ 总之就是非常可爱 S02E02.mp4
│
├─我推的孩子
│ └─S01
│ 我推的孩子 S01E01.mp4
│ 我推的孩子 S01E02.mp4
│
├─第二次被异世界召唤
│ └─S01
│ 第二次被异世界召唤 S01E01.mp4
│ 第二次被异世界召唤 S01E02.mp4
│
└─英雄联盟:双城之战
└─S01
英雄联盟:双城之战 S01E01.mp4
英雄联盟:双城之战 S01E02.mp4
英雄联盟:双城之战 S01E03.mp4
英雄联盟:双城之战 S01E04.mp4
英雄联盟:双城之战 S01E05.mp4
英雄联盟:双城之战 S01E06.mp4
英雄联盟:双城之战 S01E07.mp4
英雄联盟:双城之战 S01E08.mp4
英雄联盟:双城之战 S01E09.mp4